Phần 0. Đôi nét về Xác suất
Phần 1. Ý nghĩa của Thống kê
Phần 2. Kiểm định sử dụng mô hình Xác suất
Phần 3. Mô hình thống kê
Phần 4. Thu thập dữ liệu
Phần 5. Một vài kiểm định cơ bản
Bạn đang đọc: Xác suất thống kê – Hiểu sâu hơn về Suy luận Thống kê
= = =
Phần 0. Đôi nét về Xác suất
0.1 Ví dụ
Xác suất là việc định lượng năng lực sẽ xảy ra của một sự kiện trong đời sống, dựa trên những quy tắc toán học để dự báo, ước đạt. Nói cách khác, xác suất đo đạc mức độ không chắc như đinh ( uncertainty ) của một sự kiện .
” Khả năng thời điểm ngày hôm nay trời mưa là 30 % ” là một đánh giá và nhận định mà định lượng cảm nhận về năng lực trời mưa. Xác suất luôn được gán cho 1 số ít từ khoảng chừng [ 0, 1 ] ( hoặc tỷ suất Phần Trăm từ 0 đến 100 % ). Con số cao hơn cho thấy tác dụng có nhiều năng lực hơn số lượng thấp hơn. 0 cho biết hiệu quả sẽ không xảy ra. Xác suất 1 cho thấy tác dụng chắc như đinh sẽ xảy ra .
Có 3 phương pháp chủ yếu để gán xác định xác suất cho một kết quả, sự kiện, đó là: phương pháp cổ điển (classical method), tần suất tương đối (relative frequency method) và phương pháp chủ quan (subjective method).
Phương pháp cổ xưa để gán xác suất là tương thích khi tổng thể những hiệu quả đều có năng lực xảy ra như nhau. Nếu hoàn toàn có thể xay ra n tác dụng thử nghiệm, từng tác dụng thử nghiệm có xác suất là 1 / n .Phương pháp tần suất tương đối được sử dụng khi tài liệu có sẵn để ước tính số lần tác dụng thử nghiệm sẽ xảy ra nếu thí nghiệm được lặp đi lặp lại rất nhiều lần. Ví dụ, khi ta tung đồng xu đến hàng ngàn lần, thì xác suất để đồng xu ở mặt ngửa là 0.5. Dù cách hiểu theo lối tần suất này dễ hiểu, nhưng hạn chế ở điểm : không phải sự kiện nào trong đời sống cũng hoàn toàn có thể lặp đi lặp lại ( ví dụ, xác suất để A được bầu chọn làm Tổng thống ) .
Phương pháp chủ quan là thích hợp nhất trong trường hợp không thể thực tế cho rằng các kết quả thử nghiệm có khả năng như nhau và khi có ít dữ liệu liên quan. Khi phương pháp chủ quan được sử dụng để gán xác suất cho kết quả thử nghiệm, ta có thể sử dụng bất kỳ thông tin nào có sẵn, chẳng hạn như kinh nghiệm hoặc trực giác của mình. Sau khi xem xét tất cả các thông tin có sẵn, chỉ định một giá trị xác suất thể hiện mức độ tin tưởng (degree of belief) (trên thang điểm từ 0 đến 1) rằng kết quả thử nghiệm sẽ xảy ra. Bởi vì xác suất chủ quan thể hiện mức độ niềm tin của một người, nó mang tính cá nhân. Sử dụng phương pháp chủ quan, những người khác nhau có thể được dự kiến sẽ gán các xác suất khác nhau cho cùng một kết quả thử nghiệm.
Lý thuyết về xác suất giúp ta hoàn toàn có thể đưa ra quyết định hành động tốt hơn trong những điều kiện kèm theo bất định trong đời sống .
Đọc thêm:
0.2 Định nghĩa về mô hình xác suất
Một mô hình xác (probability model) suất bao gồm:
+ Không gian mẫu (sample space): bao gồm tất cả kết qủa có thể xảy ra
Ví dụ, một khoảng trống mẫu của thời tiết trong ngày là { nắng, mưa, âm u }
Không gian mẫu rời rạc (discreet) bao gồm hữu hạn các phần tử và không gian mẫu liên tục (continuous) bao gồm vô hạn các phần tử. Ví dụ, không gian mẫu về thời tiết là hữu hạn, nhưng không gian mẫu về chiều cao của dân số Việt Nam là liên tục.
+ Sự kiện (events): là tập con của không gian mẫu
Ví dụ, khoảng trống mẫu { nắng, mưa, âm u } có sự kiện { nắng }, { mưa }, { âm u }, { nắng, âm u }, { mưa, âm u }, { nắng, mưa }, { nắng, mưa, âm u } .
+ Phép đo xác suất (Probability measure): thể hiện xác suất của các sự kiện. Phép đo xác suất, hay phân phối xác suất (probability distribution) là một hàm P mà gán một số thực P(A) cho mỗi sự kiện A. Ta sẽ tìm hiểu kĩ hơn ở mục 0.4. phương pháp cổ điển, tần suất tương đối và phương pháp chủ quan.
0.3 Biễn ngẫu nhiên (Random variable)
Biến ngẫu nhiên của một quy mô xác suất là một hàm gắn 1 giá trị số ( numeric value ) cho một giá trị trong khoảng trống mẫu. Ví dụ, gọi X là hàm số giới tính của người dân thành phố A. Không gian mẫu ( gần như là tập xác lập của hàm số ) là { Nam, Nữ, Khác }. Khi đó, ta có X ( Nam ) = 2 triệu, X ( Nữ ) = 2.5 triệu, X ( Khá ) = 0.3 triệu. Hay ta hoàn toàn có thể viết, Dân_số_VN ( Nam ) = 2 triệu ; Dân_số_VN ( Nữ ) = 2.5 triệu. Hoặc theo cách khác, f ( x ) = Dân_số_VN. f ( Nam ) = 2 triệu ; f ( Nữ ) = 2.5 triệu .Xác suất của biến ngẫu nhiên là xác suất xảy ra sự kiện .Ví dụ. S = { nắng, mưa, âm u }. Gắn X là thời tiết trong tuần. X ( nắng ) = 3 ; X ( mưa ) = 2 ; X ( âm u ) = 2 ; X = 3 khi trời nắng ; X = 2 khi trời mưa, và X = 2 khi trời âm u. Nếu P. ( mưa ) = 0.4 ; P. ( nắng ) = 0.3 ; P. ( âm u ) = 0.3. Thi P ( X = 3 ) = P. ( nắng ) = 0.4 ; P. ( X = 4 ) = P. ( mưa ) = 0.4 ; P. ( X = – 1 ) = P. ( âm u ) = 0.3 .Một ví dụ khác, lật một đồng xu hai lần và gọi X là số lượng mặt ngửa. Sau đó, P. ( X = 0 ) = P. ( { X X } ) = 1/4, P. ( X = 1 ) = P. ( { XN, NX } ) = 50% và P. ( X = 2 ) = P. ( { HH } ) = 1/4 .Biến ngẫu nhiên gồm có biến ngẫu nhiên rời rạc ( discreet ) và liên tục ( continuous ) .
Đọc thêm:
0.4 Phân phối xác suất (probability distribution)
Nhắc lại, Phân phối xác suất hay phép đo xác suất của biến ngẫu nhiên X là sự miêu tả xác suất của những giá trị hoàn toàn có thể có của X. Hay hoàn toàn có thể nói, là của hàm số X ( với biến số là hiệu quả đầu ra ). Một cách định nghĩa khác, phép đo xác suất, hay phân phối xác suất là một hàm P. mà gán 1 số ít thực P ( A ) cho mỗi sự kiện A. Như vậy, phân phối xác suất là một hàm số, mà ” biến ” một giá trị của hàm số X với một giá trị xác suất tương ứng nằm trong khoảng chừng [ 0 ; 1 ] .Người ta sử dụng hàm phân phối dồn tích ( cumulative distribution functions, CDF ) để diễn đạt phân phối xác suất của biến ngẫu nhiên .
Ngoài ra, người ta còn sử dụng hàm xác suất (probability function), đối với biến ngẫu nhiên rời rạc, thì gọi là probability mass function, đối với biến liên tục là hàm mật độ xác suất (probability density function). Xác suất này được biểu trưng bởi tích phân, tức là phần diện tích dưới hàm mật độ xác suất. Do đó, xác suất để X tại một điểm bất kì bằng 0, còn xác suất để X thuộc khoảng (a; b) là tích phân của hàm mật độ xác suất từ a tới b.
Probability mass function của một biến ngẫu nhiên rời rạc là sự đổi khác của CDF tại một giá trị xác lập. Đối với biến liên tục, hàm tỷ lệ xác suất là đạo hàm của hàm CDF. ( Đọc thêm tại Applied Statistics for Engineering ) .
Đối với biến ngẫu nhiên, bất kể rời rạc hay liên tục, người ta quan tâm tới các tham số, như giá trị trung bình (mean), hay giá trị kì vọng (expected value), phương sai (variance) và độ lệch chuẩn (standard deviation) của biến ngẫu nhiên đó. Đồng thời, ta cũng quan tâm tới các dạng phân phối xác suất điển hình, được sử dụng rộng rãi trong Thống kê, như phân phối chuẩn (normal distribution), phân phối chi-bình phương (chi-square distribution).
1. Ý nghĩa của Thống kê
Cùng khám phá ví dụ về Nghiên cứu sự hiệu suất cao của chương trình ghép tim của Đại học Stanford. Nghiên cứu này nhằm mục đích Kết luận xem liệu chương trình ghép tim của Đại học Stanford có mang lại hiệu suất cao như đã dự tính không, tức là ngày càng tăng tuổi thọ của bệnh nhân. Nói cách khác, câu hỏi nghiên cứu và điều tra đề ra là, liệu một bệnh nhân được ghép tim có sống lâu hơn so với một bệnh nhân không được ghép tim hay không .
Đọc thêm:
Khi xem xét gật đầu một giải pháp điều trị y tế mới được đề xuất kiến nghị cho một căn bệnh, ta cần xem xét những yêu tố như những cải tổ của chiêu thức điều trị, ngân sách, cũng như đau đớn sẽ gây ra thêm cho bệnh nhân. Nếu giải pháp điều trị mới chỉ tạo ra một nâng cấp cải tiến nhỏ, thì hoàn toàn có thể không có giá trị nếu nó rất tốn kém hoặc gây thêm nhiều đau đớn cho bệnh nhân .Ta không khi nào hoàn toàn có thể biết liệu một bệnh nhân đã nhận được trái tim mới có sống lâu hơn vì cấy ghép so với việc không triển khai cấy ghép hay không. Vì vậy, kỳ vọng duy nhất trong việc xác lập sự hiệu suất cao của giải pháp điều trị có hiệu suất cao là so sánh tuổi thọ của bệnh nhân đã được ghép tim mới với tuổi thọ của bệnh nhân không cấy ghép. Tuổi thọ của một bệnh nhân bị tác động ảnh hưởng bởi nhiều yếu tố, nhiều trong số đó sẽ không tương quan gì đến sức khỏe thể chất của tim. Ví dụ, mỗi bệnh nhân có sự sai khác rất nhiều về lối sống hay mắc những bệnh lý khác, và điều này sẽ có ảnh hưởng tác động lớn tới sự sai khác về tuổi thọ giữa những bệnh nhân. Vậy làm thế nào để hoàn toàn có thể so sánh, vấn đáp câu hỏi điều tra và nghiên cứu đã đặt ra ?
Một cách tiếp cận vấn đề này là tưởng tượng rằng có phân phối xác suất (probability distribution) mô tả tuổi thọ của hai nhóm bệnh nhân. Gọi mật độ fT và fC là phân phối xác suất của 2 nhóm, trong đó T biểu thị cho nhóm được cấy ghép và C biểu thị cho nhóm không được ghép. Ở đây, dùng nhãn C bởi vì nhóm này được coi là một kiểm soát (control) trong nghiên cứu để đưa ra một số so sánh với việc điều trị (ghép tim). Sau đó, coi tuổi thọ của một bệnh nhân được cấy ghép như một quan sát ngẫu nhiên từ fT và tuổi thọ của một bệnh nhân không được cấy ghép như một quan sát ngẫu nhiên từ fC. Do vậy, ta muốn so sánh fT và fC để xác định liệu cấy ghép có hiệu quả hay không. Ví dụ, ta có thể tính và so sánh tuổi thọ trung bình của mỗi phân phối. Nếu tuổi thọ trung bình của fT lớn hơn fC, thì có thể khẳng định rằng việc điều trị là hiệu quả. Tất nhiên, ta vẫn sẽ phải đánh giá liệu cải tiến có đủ lớn để vượt qua chi phí tăng thêm và tăng phần đau đớn của bệnh nhân hay không.
Nếu tất cả chúng ta hoàn toàn có thể có một số lượng lớn những quan sát tùy ý từ fT và fC, thì ta hoàn toàn có thể xác lập những phân phối này với độ đúng mực cao. Tuy nhiên, trong trong thực tiễn, ta bị hạn chế với một số lượng quan sát tương đối nhỏ. Ví dụ, trong điều tra và nghiên cứu được trích dẫn có 30 bệnh nhân trong nhóm người không được cấy ghép và 52 bệnh nhân trong nhóm người đã được cấy ghép .Đối với mỗi bệnh nhân không được cấy ghép, giá trị của X – số ngày họ còn sống sau ngày họ được xác lập là ứng viên cho ca ghép tim cho đến khi ngày kết thúc điều tra và nghiên cứu – đã được ghi lại. Vì nhiều nguyên do, những bệnh nhân này đã làm không nhận được trái tim mới, ví dụ, họ đã chết trước khi một trái tim mới hoàn toàn có thể được tìm thấy cho họ. Những tài liệu này, cùng với một chỉ báo về thực trạng của bệnh nhân khi chấm hết ngày điều tra và nghiên cứu, được trình diễn trong Bảng 5.1. Giá trị chỉ báo S = a bộc lộ rằng Bệnh nhân còn sống khi kết thúc điều tra và nghiên cứu và S = d bộc lộ rằng bệnh nhân đã chết .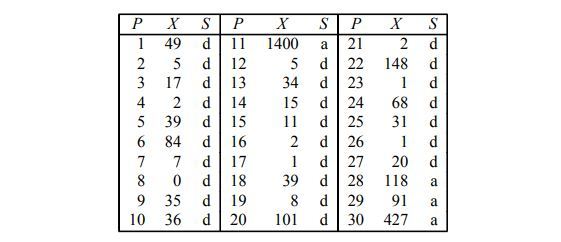 Bảng 5.1: Bảng mô tả số ngày sống, tình trạng của bệnh nhân không được cấy ghép Đối với mỗi bệnh nhân điều trị, giá trị của Y, số ngày họ chờ đón ghép sau ngày họ được xác lập là ứng viên cho ca ghép tim, và giá trị của Z, số ngày họ còn sống sau ngày họ nhận được ghép tim cho đến ngày kết thúc nghiên cứu và điều tra, cả hai đều được ghi lại. Các thời hạn sống sót cho nhóm điều trị sau đó được đưa ra bởi những giá trị của Y + Z. Dữ liệu này, cùng với một chỉ báo về thực trạng của bệnh nhân tại ngày kết thúc điều tra và nghiên cứu, được trình diễn trong Bảng 5.2 .
Bảng 5.1: Bảng mô tả số ngày sống, tình trạng của bệnh nhân không được cấy ghép Đối với mỗi bệnh nhân điều trị, giá trị của Y, số ngày họ chờ đón ghép sau ngày họ được xác lập là ứng viên cho ca ghép tim, và giá trị của Z, số ngày họ còn sống sau ngày họ nhận được ghép tim cho đến ngày kết thúc nghiên cứu và điều tra, cả hai đều được ghi lại. Các thời hạn sống sót cho nhóm điều trị sau đó được đưa ra bởi những giá trị của Y + Z. Dữ liệu này, cùng với một chỉ báo về thực trạng của bệnh nhân tại ngày kết thúc điều tra và nghiên cứu, được trình diễn trong Bảng 5.2 .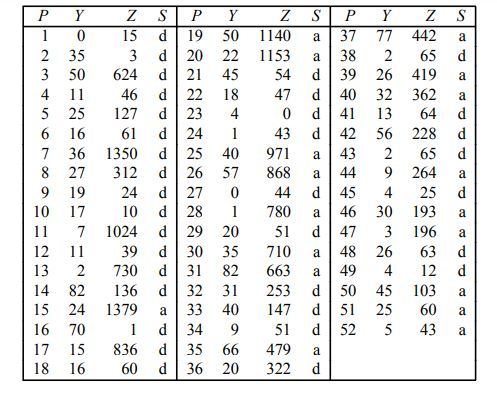 Bảng 5.2 Bảng mô tả số ngày sống, tình trạng của bệnh nhân được cấy ghép
Bảng 5.2 Bảng mô tả số ngày sống, tình trạng của bệnh nhân được cấy ghép
Ta không thể so sánh trực tiếp fT và fC vì ta không biết các phân phối này. Nhưng ta có một số thông tin về những phân phổi này bởi vì ta đã thu được các giá trị từ mỗi phân phối, như được trình bày trong Bảng 5.1 và 5.2. Vậy làm thế nào để ta sử dụng những dữ liệu này để so sánh fT và fC để trả lời câu hỏi quan trọng nhất về sự hiệu quả của điều trị ghép tim. Đây là lĩnh vực của thống kê và lý thuyết thống kê, cụ thể là, cung cấp các phương pháp để suy luận về phân phối xác suất chưa biết dựa trên việc quan sát (hoặc lấy mẫu) có được từ các phân phối xác suất.
Lưu ý rằng ví dụ này đã được đơn giản hóa phần nào, mặc dầu ví dụ trên trình diễn thực chất của yếu tố. Trong trong thực tiễn, yếu tố sẽ phức tạp hơn khi nhà thống kê sẽ có sẵn những tài liệu bổ trợ về mỗi bệnh nhân, như tuổi, giới tính và tiền sử bệnh. Ví dụ, trong Bảng 5.2 ta có những giá trị của cả Y và Z cho mỗi bệnh nhân trong nhóm điều trị .
Ví dụ trên đưa ra một số bằng chứng cho thấy các câu hỏi có tầm quan trọng thực tiễn lớn đòi hỏi phải sử dụng tư duy và phương pháp luận thống kê. Có nhiều tình huống trong khoa học vật lý và xã hội trong đó thống kê đóng vai trò then chốt. Thành phần trọng tâm trong tất cả đây là những gì chúng ta phải đối mặt với sự không chắc chắn (uncertainty). Sự không chắc chắn này được gây ra bởi cả sự biến động (variation), điều mà có thể được mô hình hóa thông qua xác suất, và bởi thực tế là chúng ta không thể thu thập đủ quan sát để biết chính xác các mô hình xác suất (probability models). Mô hình toán học được xây dựng và sử dụng để xử lí với các biến động gây ra sự không chắc chắn. Trong chương này trình bày Thống kê như một phương pháp để xử lí sự không chắc chắn gây ra bởi yếu tố, ta không thể thu thập toàn bộ quan sát.
Tóm tắt mục 1
• Thống kê được vận dụng cho những trường hợp trong đó câu hỏi điều tra và nghiên cứu không hề vấn đáp một cách chắc như đinh, thường là do sự biến hóa trong tài liệu .
• Xác suất được sử dụng để mô hình hóa các biến động (variation) quan sát được trong dữ liệu. Suy luận thống kê liên quan đến việc sử dụng dữ liệu quan sát được để giúp xác định phân phối xác suất thực (true probability distribution) tạo ra bởi các biến động này và do đó có được cái nhìn sâu sắc cho các câu trả lời cho các câu hỏi quan tâm.
Ghi chú của người dịch : Như vậy, ta giả sử rằng tài liệu có một dạng phân phối, được đặc trưng bởi những tham số. Bộ môn Xác suất giúp ta màn biểu diễn phân phối của tài liệu dưới ngôn từ Toán học. Tuy nhiên, trong trong thực tiễn, ta không hề thu thập toàn bộ quan sát của phân phối, nên không hề biết chính phân phối xác suất của tài liệu là gì. Từ những quan sát hạn chế tích lũy được, ta sử dụng Thống kê để Dự kiến phân phối thật của tài liệu .
Đọc thêm:
2. Suy luận sử dụng mô hình xác suất (probability model)
Như đã đề cập, Xác suất giúp thống kê giám sát hay định lượng sự không chắc như đinh .
Tất nhiên, ta không chắc chắn về nhiều thứ và cũng không thể cho rằng xác suất có thể áp dụng cho tất cả các tình huống. Tuy nhiên, ta giả sử cảm thấy có thể áp dụng Xác suất cho tình huống gặp phải và khi đó, xác định một phép đo xác suất P dựa trên tập hợp các tập hợp con của không gian mẫu S cho một kết quả (response hay outcome) s.
Trong ứng dụng xác suất, giả sử rằng P đã biết và ta không chắc chắn về một kết quả tương lai s ∈ S. Trong bối cảnh như vậy, ta có thể buộc phải hoặc muốn đưa ra suy luận (inference) về giá trị chưa biết của s. Ta sẽ phải dự đoán (prediction) hoặc ước lượng (estimate) giá trị hợp lý cho s, ví dụ, dưới điều kiện phù hợp, ta có thể lấy giá trị kì vọng của s như kết quả dự đoán. Trong các trường hợp khác, ta có thể phải xây dựng một tập hợp con có xác suất cao chứa s, ví dụ, tìm một vùng (region) bao gồm ít nhất 95% xác suất và có kích thước nhỏ nhất trong số tất cả các vùng như vậy. Ngoài ra, chúng ta có thể được yêu cầu để đánh giá liệu giá trị đã nêu s0 có phải là giá trị không hợp lý từ P đã biết hay không, ví dụ, đánh giá xem có hay không s0 nằm trong vùng được xác định thấp bởi P và do đó là không thể tin được. Đây là những ví dụ về suy luận có liên quan đến các ứng dụng của lý thuyết xác suất.
Tóm tắt mục 2
• Các quy mô xác suất được sử dụng để quy mô sự không chắc như đinh về những tác dụng trong tương lai .• Chúng ta hoàn toàn có thể sử dụng phân phối xác suất để Dự kiến tác dụng trong tương lai hoặc nhìn nhận xem có hợp lý khi cho rằng một giá trị nhất định là một giá trị tương lai hoàn toàn có thể có từ phân phối hay không .
3. Mô hình Thống kê
Trong một vấn đề thống kê, ta phải đối mặt với sự không chắc chắn của một yếu tố khác với các yếu tố trong Mục 2. Trong ngữ cảnh thống kê, ta quan sát dữ liệu s, nhưng lại không chắc chắn về P. Trong tình huống như vậy, ta xây dựng các suy luận về P dựa trên trên s. Đây là nghịch đảo của tình huống được thảo luận trong Mục 2.
Làm thế nào để đưa ra những suy luận thống kê (Statistical inferences) có lẽ không rõ ràng chút nào. Trong thực tế, có một số cách tiếp cận có thể sử dụng sẽ được thảo luận trong các chương tiếp theo. Trong chương này, ta sẽ tìm hiểu các thành phần cơ bản của mọi phương pháp tiếp cận.
Gần như tất cả các phương pháp tiếp cận suy luận thống kê là khái niệm về mô hình thống kê (statistical model) cho dữ liệu s. Khái niệm này có dạng một tập các phép đo xác suất, kí hiệu {Pθ: θ ∈ *}, một trong số đó tương ứng với phép đo xác suất chưa biết thực sự (true unknown probability measure) mà tạo ra dữ liệu s. Nói cách khác, ta đang khẳng định rằng có một cơ chế ngẫu nhiên (random mechanism) tạo s và chúng ta biết rằng phép đo xác suất tương ứng P là một trong những phép xác suất trong {Pθ: θ ∈ *}. Lưu ý, kí hiệu * là dùng thay cho kí hiệu chỉ tập nhưng Spiderum không hiển thị được :(.
Có 2 loại quy mô thống kê : chứa tham số và không chứa tham số. Mô hình thống kê chứa tham số ( parametric Mã Sản Phẩm ) là một tập hợp mà hoàn toàn có thể được màn biểu diễn bằng một số lượng hữu hạn những tham số. Các phân phối xác suất trong nó được trình diễn bằng những tham số. Mục tiêu của quy mô thống kê là sử dụng suy luận thống kê để tìm được tham số ” thực sự “, tức là tìm được phân phối xác suất thực sự đã sinh ra tài liệu s. Mô hình thống kê không chứa tham số ( nonparametric Model ) là tập hợp mà không hề màn biểu diễn bằng hữu hạn tham số .
Mô hình thống kê {Pθ: θ ∈ *} tương ứng với thông tin liên quan đến phép đo xác suất thực sự là gì. Biến θ được gọi là tham số (parameter) của mô hình, và tập hợp * được gọi là không gian tham số (parameter space) . Thông thường, ta sử dụng các mô hình trong đó, θ ∈ * định danh các phép đo xác suất trong mô hình, tức là, Pθ1 = Pθ2 khi và chỉ khi θ1 = θ2. Nếu tất cả các phép đo xác suất Pθ đều có thể được biểu diễn thông qua các hàm xác suất hoặc hàm mật độ fθ (để thuận tiện, ta sẽ không phân biệt giữa trường hợp biến rời rạc và liên tục trong ký hiệu), thì thông thường, mô hình thống kê được viết là {fθ: θ ∈ *}.
Từ định nghĩa của một mô hình thống kê, ta thấy rằng có một giá trị duy nhất θ ∈ *, sao cho Pθ là phép đo xác suất thực (true probability measure). Ta coi giá trị này là giá trị tham số thực (true parameter value). Nó rõ ràng tương đương với việc đưa ra suy luận về giá trị tham số thực hơn là phép đo xác suất thực, nghĩa là, đưa ra suy luận về giá trị thực tham số θ cũng đồng thời là suy luận về phân phối xác suất thực. Vì vậy, ví dụ, ta có thể ước lượng giá trị thực của θ, xây dựng các vùng nhỏ trong * mà có khả năng chứa giá trị thực hoặc đánh giá liệu dữ liệu có ủng hộ hay không với một số giá trị cụ thể, được coi là giá trị thực, θ0. Đây là những loại suy luận, có nét tương đồng với những gì đã thảo luận trong Phần 2, nhưng tình huống ở đây khá là khác nhau.
Ví dụ 3.1
Giả sử tất cả chúng ta có một chiếc bình chứa 100 chip, mỗi chip hoặc màu đen ( Đ ) hoặc trắng ( T ). Giả sử thêm rằng ta được biết có 50 hoặc 60 chip đen trong chiếc bình. Các chip được trộn kỹ, và sau đó 2 chip được rút mà không được rút lại. Mục tiêu là đưa ra suy luận về số lượng chip đen thực sự trong chiếc bình, khi đã quan sát tài liệu s = ( s1, s2 ), trong đó si là màu của chip thứ i được rút ra khỏi bình .Trong trường hợp này, tất cả chúng ta hoàn toàn có thể lấy quy mô thống kê là { Pθ : θ ∈ * }, trong đó θ là số lượng chip đen trong bình, sao cho * = { 50, 60 } và Pθ là phép đo xác suất trên S = { ( Đ, Đ ), ( Đ, T ), ( T, Đ ), ( T, T ) } .
Do đó, P50 được gán cho xác suất 50 · 49 / (100 · 99) cho mỗi chuỗi (Đ, Đ) và (T, T) và xác suất 50 · 50 / (100 · 99) cho mỗi các chuỗi (Đ, T) và (T, Đ) và P60 gán xác suất 60 · 59 / (100 · 99) cho chuỗi (Đ, Đ), xác suất 40 · 39 / (100 · 99) cho chuỗi (T, T) và xác suất 60 · 40 / (100 · 99) cho mỗi chuỗi (Đ, T) và (T, Đ). Việc lựa chọn tham số này có phần tùy ý, vì chúng ta có thể dễ dàng gắn nhãn các phép đo xác suất có thể tương tự như P1 và P2. Tham số về bản chất chỉ là một nhãn cho phép ta phân biệt giữa các ứng viên tiềm năng cho phép đo xác suất thực. Tuy nhiên, thông thường phải chọn nhãn một cách phù hợp sao cho nhãn có nghĩa nào đó trong vấn đề đang thảo luận.
Lưu ý rằng, ta sẽ sử dụng chữ in hoa để biểu lộ một giá trị không quan sát được của một biến ngẫu nhiên X và chữ thường để bộc lộ giá trị quan sát được. Vì vậy, một mẫu quan sát được ( X1, …, Xn ) sẽ được ký hiệu ( x1, …, xn ) .Tuy nhiên, trong nhiều ứng dụng, tham số θ được coi là 1 số ít đặc thù của phân phối mà nhận một giá trị duy nhất cho mỗi phân phối trong quy mô. Ví dụ, một hàm xác suất được biểu lộ là ta hoàn toàn có thể lấy θ là giá trị trung bình và sau đó khoảng trống tham số sẽ là * = { 1, 1.5 } .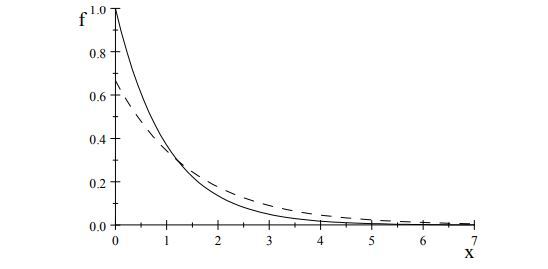 Hình 3.1 Nét liền là hàm phân phôi Exponential(1), Nét đứt là hàm phân phối Exponential(2)Lưu ý rằng ta cũng hoàn toàn có thể sử dụng phần tư tiên phong, hoặc cho yếu tố đó bất kỳ phần tư nào khác, để gắn nhãn cho phân phối, với điều kiện kèm theo mỗi phân phối trong họ phân phối sẽ đưa ra một giá trị duy nhất cho đặc trưng được lựa chọn. Nói chung, bất kể quy đổi 1-1 nào của một tham số đều được đồng ý như sự tham số hóa ( parameterization ) của một quy mô thống kê. Khi ta gán nhãn lại, ta gọi điều này là xác lập lại tham số ( reparameterization ) của quy mô thống kê .Bây giờ ta xem xét 1 ví dụ quan trọng của những quy mô thống kê .
Hình 3.1 Nét liền là hàm phân phôi Exponential(1), Nét đứt là hàm phân phối Exponential(2)Lưu ý rằng ta cũng hoàn toàn có thể sử dụng phần tư tiên phong, hoặc cho yếu tố đó bất kỳ phần tư nào khác, để gắn nhãn cho phân phối, với điều kiện kèm theo mỗi phân phối trong họ phân phối sẽ đưa ra một giá trị duy nhất cho đặc trưng được lựa chọn. Nói chung, bất kể quy đổi 1-1 nào của một tham số đều được đồng ý như sự tham số hóa ( parameterization ) của một quy mô thống kê. Khi ta gán nhãn lại, ta gọi điều này là xác lập lại tham số ( reparameterization ) của quy mô thống kê .Bây giờ ta xem xét 1 ví dụ quan trọng của những quy mô thống kê .
Ví dụ 3.2 Mô hình Bernoulli
Giả sử rằng (x1, …, xn) là một mẫu từ phân phối Bernoulli (θ) với θ ∈ [0, 1]
không xác định. Chúng ta có thể quan sát kết quả tung đồng xu và ghi Xi bằng 1 nếu khi nào quan sát được mặt ngửa ở lần tung thứ i và bằng 0 nếu ngược lại. Ngoài ra, ta cũng có thể quan sát các mặt hàng được sản xuất trong một quy trình công nghiệp và ghi lại Xi bằng 1 nếu mặt hàng thứ i bị lỗi và 0 nếu ngược lại. Trong tất cả các trường hợp này, ta muốn biết giá trị thực của θ, vì điều này cho chúng ta biết một điều quan trọng về đồng tiền mà chúng ta đang tung, hoặc quá trình công nghiệp.
Bây giờ giả sử ta không có thông tin gì về xác suất thực sự. Theo đó, ta lấy khoảng trống tham số là * = [ 0, 1 ], là tập hợp toàn bộ những giá trị hoàn toàn có thể cho θ. Hàm xác suất cho mục mẫu thứ i được đưa ra bởi công thức :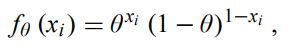
và hàm xác suất cho mẫu được đưa ra bởi công thức :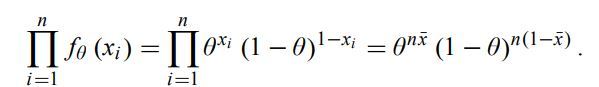
Câu hỏi đặt ra là thông tin về mô hình {Pθ: ∈ *} đến từ đâu trong một trường hợp ứng dụng xác suất? Làm thế nào để xác định một mô hình thống kê cho dữ liệu? Đôi khi có những thông tin như vậy dựa trên kinh nghiệm trước đó, nhưng thường thì đó là một giả định cần kiểm tra trước khi áp dụng quy trình suy luận. Trong thực tế, quy trình kiểm tra các giả định đó, hay gọi là quy trình kiểm tra mô hình (model-checking procedures) bắt buộc thực hiện trước quá trình suy luận. Nếu mô hình sai, các suy luận khác được rút ra từ dữ liệu và mô hình thống kê có thể bị lỗi.
Tóm tắt mục 3
• Trong một ứng dụng thống kê, ta không biết phân phối của hiệu quả, nhưng ta biết ( hoặc giả định ) rằng phân phối xác suất thực sự là một trong những tập hợp những phân phối hoàn toàn có thể { fθ : ∈ * }, trong đó fθ là hàm tỷ lệ hoặc hàm xác suất ( bất kể điều gì có tương quan ) cho hiệu quả đó. Tập hợp những phân phối hoàn toàn có thể có được gọi là quy mô thống kê .• Tập * được gọi là khoảng trống tham số và biến θ được gọi là tham số của quy mô. Bởi vì mỗi giá trị của θ tương ứng với một phân phối xác suất riêng không liên quan gì đến nhau trong quy mô, tất cả chúng ta hoàn toàn có thể nói về giá trị thực của θ, tương tự với phân phối thực qua fθ .
4. Thu thập dữ liệu
Sự tăng trưởng của Phần 2 và 3 dựa trên biến nhờ vào được quan sát được ghi nhận từ một phép đo xác suất P. Trên trong thực tiễn, trong nhiều ứng dụng, đây là một giả định. Ta tiếp tục phát hiện những tài liệu hoàn toàn có thể được tạo ra theo cách này, nhưng ta không hề luôn luôn chắc như đinh về điều đó .
Khi ta không thể chắc chắn rằng dữ liệu được tạo ra bởi một cơ chế ngẫu nhiên, thì phân tích thống kê về dữ liệu được gọi là một nghiên cứu quan sát (observational study). Trong một nghiên cứu quan sát, nhà thống kê chỉ quan sát dữ liệu chứ không can thiệp trực tiếp can thiệp vào việc tạo ra dữ liệu, để đảm bảo rằng giả định ngẫu nhiên giữ vững. Ví dụ, giả sử một giáo sư thu thập dữ liệu từ các sinh viên của mình cho một nghiên cứu xem xét mối quan hệ giữa các lớp và việc làm bán thời gian. Có hợp lý không để coi như dữ liệu thu thập được đã đến từ một phân phối xác suất? Nếu vậy, làm thế nào chúng ta sẽ giải thích hợp lí cho điều này?
Điều quan trọng là một nhà thống kê phải phân biệt cẩn trọng giữa những trường hợp là những điều tra và nghiên cứu quan sát và những trường hợp không phải điều tra và nghiên cứu quan sát. Như những cuộc luận bàn sau đây minh họa, có những tiêu chuẩn phải được vận dụng để nghiên cứu và phân tích một điều tra và nghiên cứu quan sát. Trong khi những nghiên cứu và phân tích thống kê của những điều tra và nghiên cứu quan sát là hợp lệ và thực sự quan trọng, ta phải nhận thức được những hạn chế của họ khi diễn giải hiệu quả đó .
4.1 Tổng thể hữu hạn
Giả sử ta có tập hữu hạn II, được gọi là toàn diện và tổng thể ( population ) và hàm X có giá trị thực ( đôi lúc được gọi là phép đo – measurement ) được xác lập trên II. Vì vậy, với mỗi π ∈ II, tất cả chúng ta có đại lượng X ( π ) có giá trị thực giám sát 1 số ít góc nhìn của π. ( Lưu ý : một nhóm những biến ngẫu nhiên X1, X2, .., Xn được gọi là phân phối giống hệt độc lập ( independent and identically distributed, kí hiệu II ) nếu nhóm đó độc lập và mỗi một biến trong n biến này có phân phối giống nhau ) .Xét một ví dụ sau. Giả sử, II là một toàn diện và tổng thể có N = 20 lô đất cùng kích cỡ. Tiếp tục giả sử X ( π ) là phép đo độ phì nhiêu của lô đất π trên 10 điểm và thu được tác dụng đo sau đây :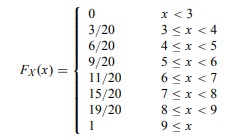 Mục tiêu của một nhà thống kê trong trường hợp này là biết hàm FX càng đúng mực càng tốt. Nếu ta biết đúng mực về FX, thì ta đã xác lập được phân phối của X trên phân phối II. Một cách để biết đúng chuẩn phân phối là triển khai tìm hiểu dân số, trong đó, nhà thống kê đi ra ngoài và quan sát X ( π ) cho mỗi π ∈ II và sau đó giám sát FX. Đôi khi điều này là khả thi, nhưng thường thì không hề hoặc thậm chí còn là không mong ước, do ngân sách về việc tổng hợp đúng mực tổng thể những phép đo – nghĩ về việc khó khăn vất vả như thế nào để tích lũy chiều cao của toàn bộ những sinh viên trong trường của bạn. Thường, việc ước đạt một cách khá đúng mực FX đạt được khi lựa chọn một tập con { π1, …, πn } .Có hai câu hỏi ta cần vấn đáp – đơn cử là, ta nên chọn tập con { π1, …, πn } như thế nào và n nên lớn bao nhiêu ?
Mục tiêu của một nhà thống kê trong trường hợp này là biết hàm FX càng đúng mực càng tốt. Nếu ta biết đúng mực về FX, thì ta đã xác lập được phân phối của X trên phân phối II. Một cách để biết đúng chuẩn phân phối là triển khai tìm hiểu dân số, trong đó, nhà thống kê đi ra ngoài và quan sát X ( π ) cho mỗi π ∈ II và sau đó giám sát FX. Đôi khi điều này là khả thi, nhưng thường thì không hề hoặc thậm chí còn là không mong ước, do ngân sách về việc tổng hợp đúng mực tổng thể những phép đo – nghĩ về việc khó khăn vất vả như thế nào để tích lũy chiều cao của toàn bộ những sinh viên trong trường của bạn. Thường, việc ước đạt một cách khá đúng mực FX đạt được khi lựa chọn một tập con { π1, …, πn } .Có hai câu hỏi ta cần vấn đáp – đơn cử là, ta nên chọn tập con { π1, …, πn } như thế nào và n nên lớn bao nhiêu ?
4.2 Lấy mẫu ngẫu nhiên đơn (Simple Random Sampling)
Trước tiên ta sẽ xử lý yếu tố chọn { π1, …, πn }. Giả sử, ta chọn tập hợp con này theo 1 số ít quy tắc nhất định dựa trên nhãn duy nhất của mỗi π ∈ II. Ví dụ, nếu nhãn là 1 số ít, ta hoàn toàn có thể xếp hạng những số và sau đó lấy n những yếu tố với những nhãn nhỏ nhất. Hoặc tất cả chúng ta hoàn toàn có thể xếp hạng những số và lấy thành phần cách nhau 1 bậc cho đến khi tất cả chúng ta có một tập con của n, v.v.Có nhiều quy tắc như vậy ta hoàn toàn có thể vận dụng, và có một yếu tố cơ bản. Nếu tất cả chúng ta muốn FˆX giao động FX cho hàng loạt toàn diện và tổng thể, thì, khi ta sử dụng một quy tắc, ta đương đầu với rủi ro đáng tiếc chỉ chọn { π1, …, πn } từ một quần thể phụ. Ví dụ, nếu ta sử dụng mã sinh viên để xác lập từng thành phần của một toàn diện và tổng thể sinh viên, và nhiều sinh viên năm 4 sẽ có mã sinh viên thấp hơn, khi đó, khi n nhỏ hơn N rất nhiều và ta chọn những sinh viên có mã sinh viên nhỏ nhất, FˆX thực sự chỉ xê dịch phân phối X trong toàn diện và tổng thể của sinh viên năm cuối tốt nhất. Phân phối này hoàn toàn có thể rất khác với FX. Tương tự, so với bất kể quy tắc nào khác ta sử dụng, ngay cả khi ta không hề tưởng tượng được tập phụ ( subpopulation ) hoàn toàn có thể là gì, ảnh hưởng tác động lựa chọn ( selection effect ), hoặc thiên kiến ( bias ) hoàn toàn có thể sống sót, gây ra ước tính không hợp lệ .Đây là trình độ trình độ ( qualification ) ta cần vận dụng khi nghiên cứu và phân tích tác dụng nghiên cứu và điều tra quan sát. Trong một điều tra và nghiên cứu quan sát, tài liệu được tạo ra bởi một số ít quy tắc, đặc biệt quan trọng là chưa được biết đến bởi những nhà thống kê ; điều này có nghĩa là bất kể Tóm lại nào được rút ra dựa trên tài liệu X ( π1 ), ,. .., X ( πn ) hoàn toàn có thể không hợp lệ cho hàng loạt dân số. Hình như chỉ có một cách để bảo vệ tránh những hiệu ứng lựa chọn, đơn cử là phải chọn tập { π1, …, πn } bằng cách sử dụng ngẫu nhiên. Đối với cách lấy mẫu ngẫu nhiên ( simple random sampling ), điều này có nghĩa là một chính sách ngẫu nhiên được sử dụng để chọn πi theo cách như vậy rằng mỗi tập con của n có xác suất 1 / # N n USD được chọn. Ví dụ, ta hoàn toàn có thể đặt N miếng khoai tây vào một cái bát, mỗi cái có một nhãn duy nhất tương ứng với một thành phần của tổng thể và toàn diện, sau đó rút ngẫu nhiên n miếng khoai tây từ bát mà không được thay thế sửa chữa. Các nhãn trên những khoai tây được rút ra xác lập những cá thể đã được chọn từ II. Ngoài ra, để ngẫu nhiên hóa, ta hoàn toàn có thể sử dụng bảng số ngẫu nhiên hoặc tạo những giá trị ngẫu nhiên sử dụng thuật toán máy tính .Lưu ý rằng với lấy mẫu ngẫu nhiên đơn thuần, ( X ( π1 ), .., X ( πn ) ) là ngẫu nhiên. Đặc biệt, khi n = 1, khi đó tất cả chúng ta có P. ( X ( π1 ) x ) = FX ( x ), đơn cử là phân phối xác suất của biến ngẫu nhiên X ( π1 ) giống như phân bổ toàn diện và tổng thể .
Bất cứ khi nào dữ liệu được thu thập bằng cách sử dụng lấy mẫu ngẫu nhiên đơn giản, chúng tôi sẽ đề cập đến điều tra thống kê như một nghiên cứu lấy mẫu (sampling study). Đó là một nguyên tắc cơ bản của thực hành thống kê tốt rằng các nghiên cứu lấy mẫu luôn được ưu tiên hơn các nghiên cứu quan sát, bất cứ khi nào chúng khả thi. Điều này là do chúng ta có thể chắc chắn rằng, với một mẫu nghiên cứu, bất kỳ kết luận nào chúng tôi rút ra dựa trên mẫu π1, …, πn sẽ áp dụng cho 1 tổng thể quan tâm. Với các nghiên cứu quan sát, ta không bao giờ có thể chắc chắn rằng mẫu dữ liệu chưa thực sự được chọn từ một số tập hợp con đúng của *. Ví dụ: nếu bạn được yêu cầu đưa ra những suy luận về sự phân bố chiều cao của học sinh tại trường của bạn nhưng đã chọn một số bạn bè của bạn làm mẫu của bạn, thì rõ ràng là CDF ước tính có thể rất không giống với CDF thật (có thể nhiều bạn bè của bạn thuộc một giới tính hơn cai khac).
Tuy nhiên, thường thì, ta không có lựa chọn nào khác ngoài sử dụng tài liệu quan sát cho thống kê nghiên cứu và phân tích. Lấy mẫu trực tiếp từ toàn diện và tổng thể chăm sóc hoàn toàn có thể cực kỳ khó khăn vất vả hoặc thậm chí còn là không hề. Ta vẫn hoàn toàn có thể coi hiệu quả của những nghiên cứu và phân tích đó là một dạng dẫn chứng, nhưng ta phải cẩn trọng về những ảnh hưởng tác động lựa chọn ( selection effects ) hoàn toàn có thể và thừa nhận năng lực này. Các điều tra và nghiên cứu lấy mẫu được coi là một vật chứng thống kê cao hơn so với quan sát điều tra và nghiên cứu, vì chúng tránh được tác động ảnh hưởng lựa chọn .Câu hỏi thứ hai ta cần xử lý tương quan đến việc lựa chọn cỡ mẫu n. Có vẻ dễ hiểu khi ta muốn chọn cỡ mẫu càng lớn càng tốt. Mặt khác, luôn có ngân sách tương quan đến lấy mẫu và nhiều lúc mỗi giá trị mẫu là rất tốn kém để có được. Hơn nữa, càng tích lũy nhiều tài liệu, ta càng gặp nhiều khó khăn vất vả hơn trong việc bảo vệ tài liệu không bị sai bởi nhiều loại lỗi hoàn toàn có thể phát sinh trong quy trình tích lũy. Vì vậy, câu vấn đáp của chúng tôi là ta muốn nó được chọn đủ lớn để có được độ đúng chuẩn thiết yếu nhưng không cần lớn hơn. Theo đó, nhà thống kê phải chỉ định mức độ đúng chuẩn bắt buộc và thì sau đó xác lập n .
Có nhiều phương pháp khác nhau để chỉ định độ chính xác cần thiết trong một vấn đề và sau đó xác định một giá trị phù hợp cho n. Xác định n là thành phần chính trong việc thực hiện nghiên cứu lấy mẫu và là thường được gọi là tính toán kích thước mẫu (sample-size calculation).
4.3 Histograms
Các biến định lượng hoàn toàn có thể được phân loại thành những biến rời rạc hoặc biến liên tục. Các biến liên tục là những biến mà ta hoàn toàn có thể đo đến độ đúng mực tùy ý khi tăng độ đúng chuẩn của một dụng cụ đo lường và thống kê. Ví dụ, độ cao của một cá thể hoàn toàn có thể được coi là một biến liên tục, trong khi số năm giáo dục một cá thể sẽ được coi là một biến định lượng rời rạc. Biểu đồ tần suất hoàn toàn có thể sử dụng cho cả biến rời rạc và biến liên tục, đặc biệt quan trọng hữu dụng cho biến liên tục .
4.4 Survey Sampling
Lấy mẫu tổng thể và toàn diện hữu hạn cung ứng công thức cho một ứng dụng rất quan trọng thống kê, đơn cử là lấy mẫu khảo sát ( survey sampling ) hoặc bỏ phiếu ( polling ). Thông thường, một cuộc khảo sát gồm có một bộ những câu hỏi được hỏi về một mẫu { π1, …, πn } từ tổng thể và toàn diện II. Mỗi câu hỏi tương ứng với một phép đo, thế cho nên nếu có m câu hỏi, câu vấn đáp từ người vấn đáp π là vectơ m chiều ( X1 ( π ), X2 ( π ), .., Xm ( π ) ). Một ví dụ rất quan trọng về lấy mẫu khảo sát là việc bỏ phiếu trước bầu cử được thực thi để Dự kiến hiệu quả của một cuộc bỏ phiếu. Ngoài ra, nhiều công ty ngành hàng tiêu dùng sử dụng những cuộc khảo sát thị trường to lớn để khám phá điều người tiêu dùng muốn và để có được thông tin giúp tăng doanh thu .Thông thường, việc nghiên cứu và phân tích tác dụng không riêng gì chăm sóc tới phân phối tổng tể của cá thể Xi mà còn phân phối tổng thể và toàn diện giao nhau ( joint population distribution ). Những phân phối chung này được sử dụng để vấn đáp cho câu hỏi như, liệu có mối quan hệ giữa X1 và X2, và nếu có, thì nó có dạng nào ? Phân phối chung đặc biệt quan trọng có ích với X1, X2 đều là biến định tính liên tục .Bài viết này chỉ dừng lại ra mắt chứ không đi sâu tới những góc nhìn của lấy mẫu khảo sát .
Tóm tắt phần 4
• Lấy mẫu ngẫu nhiên đơn thuần từ tổng thể và toàn diện II nghĩa là ta chọn ngẫu nhiên một tập con cỡ n từ II theo cách sao cho mỗi tập con có xác suất được chọn như nhau .• Dữ liệu từ nghiên cứu và điều tra lấy mẫu được tạo ra từ phân phối của phép đo biến ngẫu nhiên X trên hàng loạt toàn diện và tổng thể II hơn là một toàn diện và tổng thể nhỏ nào đó. Đó là lí do tại sao nghiên cứu và điều tra lấy mẫu được ưu thích hơn điều tra và nghiên cứu quan sát .• Khi cỡ mẫu n khá nhỏ so với kích cỡ tổng thể và toàn diện, tất cả chúng ta hoàn toàn có thể coi những giá trị quan sát được của biến ngẫu nhiên X như thể một mẫu từ phân phối X trên hàng loạt tổng thể và toàn diện .
5. Một số suy luận cơ bản
Bây giờ giả sử ta đang ở trong một trường hợp tương quan đến phép đo X, có phân phối là chưa xác lập và ta đã thu được tài liệu ( x1, x2, …, xn ), tức là, quan sát n giá trị của X. Hy vọng rằng những tài liệu này là tác dụng của việc lấy mẫu ngẫu nhiên đơn thuần, nhưng hoàn toàn có thể chúng được tích lũy từ một điều tra và nghiên cứu quan sát. Gọi hàm số tần số tương đối chưa biết của tổng thể và toàn diện, hoặc hàm tỷ lệ xê dịch là fX và hàm phân phối toàn diện và tổng thể là FX .Những gì tất cả chúng ta làm giờ đây với tài liệu phụ thuộc vào vào hai điều. Đầu tiên, tất cả chúng ta phải xác lập những gì tất cả chúng ta muốn biết về phân bổ tổng thể và toàn diện cơ bản. Điển hình là chăm sóc chỉ là một vài đặc thù của phân phối này – giá trị trung bình và phương sai. Thứ hai, ta phải sử dụng kim chỉ nan thống kê để tích hợp tài liệu với quy mô thống kê để suy luận về những đặc thù chăm sóc .
5.1 Phương pháp “không chính thức” (informal)
Bây giờ ta luận bàn về 1 số ít đặc thù nổi bật được chăm sóc và trình làng 1 số ít giải pháp không chính thức ước tính cho những đặc thù này, được gọi là thống kê miêu tả ( discriptive statistics ). Thống kê diễn đạt thường được sử dụng như một bước sơ bộ trước khi rút ra những suy luận chính thức hơn và biện minh trên cơ sở trực quan đơn thuần. Chúng được gọi là diễn đạt chính bới chúng là ước tính số lượng mà miêu tả những tính năng của phân phối cơ bản. Thống kê diễn đạt là đưa ra rất nhiều đặc thù của phân phối, như mean, median, phương sai, độ xiên, vân vân .Vẽ đồ thị ( Plotting ) giúp trực quan hóa dữ liệu, giúp ta có một vài sáng tạo độc đáo về hình dạng của phân phối được lấy mẫu. Độ xiên cũng hoàn toàn có thể được phát hiện khi vẽ đồ thị .
5.2 Phương pháp chính thức – các loại suy luận
Sử dụng Thống kê diễn đạt hay Vẽ đồ thị có những khó khăn vất vả nhất định vì việc lựa chọn những giải pháp này dựa trên trực giác của người nghiên cứu và điều tra. Thông thường, không rõ ta nên sử dụng Thống kê diễn đạt nào. Hơn nữa, những tóm tắt tài liệu này không tận dụng thông tin ta có về phân bổ dân số thực sự như quy mô thống kê, đơn cử là, fX { fθ : ∈ * }. Sử dụng những thông tin này giúp ta tăng trưởng một triết lý về suy luận thống kê, tức là, để chỉ định cách tất cả chúng ta nên tích hợp thông tin quy mô với tài liệu để suy luận về số lượng tổng thể và toàn diện .Trong mục 5.2, ta đã luận bàn về ba loại suy luận trong trường hợp quy mô xác suất đã biết, được xác lập là một hàm tỷ lệ hoặc hàm xác suất f .Trong ứng dụng thống kê, ta không biết f ; tất cả chúng ta chỉ biết rằng f thuộc về một quy mô thống kê, tức là f ∈ { fθ : θ ∈ * }, và ta quan sát tài liệu s. Ta không chắc như đinh về việc ứng viên nào cho fθ là đúng mực, hay nói cách khác, giá trị nào hoàn toàn có thể có của θ là đúng chuẩn .Như đã đề cập trong Mục 5.1, tiềm năng chính của ta là xác lập không đúng fθ thật sự, nhưng tìm ra 1 số ít đặc thù chăm sóc của phân phối thực như giá trị trung bình, trung vị hoặc giá trị của hàm phân phối thực F tại một giá trị xác lập .Ta trình diễn những đặc thù này bằng ψ ( θ ). Ví dụ, khi đặc thù được chăm sóc là giá trị trung bình của phân phối thực của một biến ngẫu nhiên liên tục, sau đó :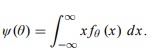 Ngoài ra, tất cả chúng ta hoàn toàn có thể chăm sóc đến ( θ ) = F − 1 ( 0,5 ), trung vị của phân phối của một biến ngẫu nhiên với hàm phân phối được đưa ra bởi Fθ .Các giá trị khác nhau của θ dẫn đến những giá trị hoàn toàn có thể khác nhau về đặc thù của ψ ( θ ). Sau khi quan sát tài liệu, ta muốn suy luận về giá trị đúng mực. Ta sẽ xem xét ba loại suy luận cho ψ ( θ .( i ) Chọn một ước đạt T ( s ) của ψ ( θ ), được gọi là yếu tố ước tính ( problem of estimation ) .( ii ) Xây dựng tập hợp con C ( s ) của tập hợp những giá trị hoàn toàn có thể cho ψ ( θ ) màta tin rằng chứa giá trị thực, được gọi là yếu tố của việc xây dừng vùng đáng đáng tin cậy ( credit region / confidence region ) .( iii ) Đánh giá xem ψ0 có phải là giá trị hài hòa và hợp lý của ψ ( θ ) hay không sau khi quan sát s, gọi là yếu tố nhìn nhận giả thuyết ( hypothesis testing ) .Vì vậy, ước tính, khu vực đáng đáng tin cậy hoặc an toàn và đáng tin cậy và nhìn nhận giả thuyết là ví dụ của những loại suy luận. Cụ thể, chúng tôi muốn kiến thiết xây dựng ước tính T ( s ) của ψ ( θ ) kiến thiết xây dựng vùng an toàn và đáng tin cậy hoặc độ an toàn và đáng tin cậy C ( s ) cho ψ ( θ ) và nhìn nhận tính hài hòa và hợp lý của một giá trị giả thuyết ψ0 cho ψ ( θ ) .Vấn đề suy luận thống kê yên cầu phải xác lập cách tất cả chúng ta nên phối hợp thông tin trong quy mô { fθ : ∈ * } và tài liệu s để thực thi những suy luận này khoảng chừng ( θ ) .Tóm tắt mục 5.5• Thống kê miêu tả đại diện thay mặt cho những chiêu thức thống kê không chính thức được sử dụng để triển khai suy luận về phân phối biến ngẫu nhiên X chăm sóc, dựa trên quan sát mẫu từ phân phối này. Các đại lượng này diễn đạt những đặc thù của mẫu quan sát và hoàn toàn có thể được coi là ước đạt của những đại lượng tổng thể và toàn diện chưa biết tương ứng. Các chiêu thức chính thức hơn bắt buộc sử dụng để nhìn nhận lỗi trong những ước đạt này hoặc thậm chí còn sửa chữa thay thế chúng bằng những ước đạt có độ đúng chuẩn hơn .• Vẽ những đồ thị tương quan là rất quan trọng. Những điều này cho ta một số ít ý tưởng sáng tạo về hình dạng của phân bổ tổng thể và toàn diện mà ta lấy mẫu từ đó .
Ngoài ra, tất cả chúng ta hoàn toàn có thể chăm sóc đến ( θ ) = F − 1 ( 0,5 ), trung vị của phân phối của một biến ngẫu nhiên với hàm phân phối được đưa ra bởi Fθ .Các giá trị khác nhau của θ dẫn đến những giá trị hoàn toàn có thể khác nhau về đặc thù của ψ ( θ ). Sau khi quan sát tài liệu, ta muốn suy luận về giá trị đúng mực. Ta sẽ xem xét ba loại suy luận cho ψ ( θ .( i ) Chọn một ước đạt T ( s ) của ψ ( θ ), được gọi là yếu tố ước tính ( problem of estimation ) .( ii ) Xây dựng tập hợp con C ( s ) của tập hợp những giá trị hoàn toàn có thể cho ψ ( θ ) màta tin rằng chứa giá trị thực, được gọi là yếu tố của việc xây dừng vùng đáng đáng tin cậy ( credit region / confidence region ) .( iii ) Đánh giá xem ψ0 có phải là giá trị hài hòa và hợp lý của ψ ( θ ) hay không sau khi quan sát s, gọi là yếu tố nhìn nhận giả thuyết ( hypothesis testing ) .Vì vậy, ước tính, khu vực đáng đáng tin cậy hoặc an toàn và đáng tin cậy và nhìn nhận giả thuyết là ví dụ của những loại suy luận. Cụ thể, chúng tôi muốn kiến thiết xây dựng ước tính T ( s ) của ψ ( θ ) kiến thiết xây dựng vùng an toàn và đáng tin cậy hoặc độ an toàn và đáng tin cậy C ( s ) cho ψ ( θ ) và nhìn nhận tính hài hòa và hợp lý của một giá trị giả thuyết ψ0 cho ψ ( θ ) .Vấn đề suy luận thống kê yên cầu phải xác lập cách tất cả chúng ta nên phối hợp thông tin trong quy mô { fθ : ∈ * } và tài liệu s để thực thi những suy luận này khoảng chừng ( θ ) .Tóm tắt mục 5.5• Thống kê miêu tả đại diện thay mặt cho những chiêu thức thống kê không chính thức được sử dụng để triển khai suy luận về phân phối biến ngẫu nhiên X chăm sóc, dựa trên quan sát mẫu từ phân phối này. Các đại lượng này diễn đạt những đặc thù của mẫu quan sát và hoàn toàn có thể được coi là ước đạt của những đại lượng tổng thể và toàn diện chưa biết tương ứng. Các chiêu thức chính thức hơn bắt buộc sử dụng để nhìn nhận lỗi trong những ước đạt này hoặc thậm chí còn sửa chữa thay thế chúng bằng những ước đạt có độ đúng chuẩn hơn .• Vẽ những đồ thị tương quan là rất quan trọng. Những điều này cho ta một số ít ý tưởng sáng tạo về hình dạng của phân bổ tổng thể và toàn diện mà ta lấy mẫu từ đó .
• Có ba loại suy luận chính: ước lượng, khoảng tin cậy hoặc độ tin cậy và đánh giá giả thuyết.
Xem thêm: Gu của anh là người mẫu
Tài liệu tham khảo
[ 1 ] Evans, M., and Rosenthal, J., 2009. Probability and Statistics : The Science of Uncertainty. 2 nd edn. Thành Phố New York : W. H. Freeman .[ 2 ] Wasserman ,. L. 2010. All of Statistics : A Concise Course in Statistical Inference. Thành Phố New York : Springer .[ 4 ] Anderson, D. R., Sweeney, D. J., and Williams, T. A., 2008. Statistics for Business and Economics. Ohio : Thomson South-Western .
Source: https://www.doom.vodka
Category: Tin tức
Leave a Reply
You must be logged in to post a comment.